

揭秘二四六香港天天开彩大全:统计解答与应用解析
在数字时代,数据无处不在,而如何从海量的数据中提取有价值的信息,成为了各行各业关注的焦点,特别是在彩票领域,通过对历史数据的统计分析,不仅可以揭示出某些潜在的规律,还能为彩民提供更为科学的选号参考,本文将深入探讨“二四六香港天天开彩大全”的相关内容,包括其背后的统计学原理、数据分析方法以及如何将这些知识应用于实际的购彩过程中。
彩票作为一种娱乐方式,在全球范围内都拥有庞大的参与者群体,香港六合彩因其独特的玩法和较高的中奖概率,吸引了众多彩民的关注,面对复杂的开奖结果,许多彩民往往感到困惑,不知道如何下手进行分析,本文旨在通过介绍一些基本的统计学知识和数据分析技巧,帮助大家更好地理解六合彩的开奖规律,从而提高选号的准确性。
二、统计学基础
1. 概率论简介
概率论是研究随机事件发生可能性大小的一门学科,在彩票分析中,了解基本的概率计算是非常重要的,知道每种号码组合出现的概率可以帮助我们评估不同投注策略的风险与收益比。
2. 描述性统计量
均值(Average):所有数值之和除以数值个数。
中位数(Median):将所有数值按大小顺序排列后位于中间位置的那个数。
标准差(Standard Deviation):反映一组数据离散程度的一个指标。
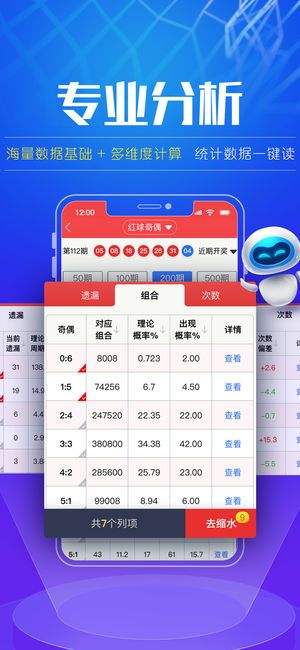
这些统计量能够帮助我们快速了解数据集的基本特征,如中心趋势及波动范围等。
三、数据采集与处理
对于想要对六合彩进行深入研究的朋友来说,首先需要收集足够多的历史开奖记录作为样本,目前市面上有许多专门提供此类信息服务的网站或应用程序,比如App37.98.14就是一个不错的选择,使用这类工具时应注意以下几点:
- 确保数据来源可靠;
- 注意检查是否存在缺失值或者异常值,并采取相应措施处理;
- 根据研究目的选择合适的时间段内的数据进行分析。
四、数据分析方法
1. 频率分布
通过对历史开奖号码的频率分布情况进行统计分析,可以发现哪些数字出现得更加频繁,虽然每次抽奖都是独立事件,但长期来看某些特定数字可能会表现出一定的偏好性。
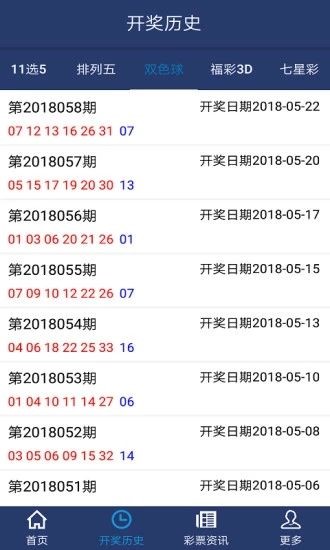
2. 趋势分析
除了静态地观察单个数字的表现外,还可以结合时间序列模型来探索随着时间推移号码变化的趋势,这样做有助于预测未来一段时间内可能出现较多次数的数字类型。
3. 相关性检验
如果涉及到多个变量之间的相互关系,则可以通过计算皮尔逊相关系数等方式来判断它们之间是否存在显著关联,这对于构建更复杂的预测模型非常有帮助。
五、案例研究
假设我们已经按照上述步骤完成了初步的数据准备工作,接下来将以具体实例的形式展示如何运用所学知识来进行实际操作,这里选取了最近一年中的部分开奖结果作为研究对象:
步骤一:导入所需库并加载数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 假设data.csv包含了所需的全部信息
df = pd.read_csv('data.csv')步骤二:查看基本信息
print(df.head()) print(df.describe())
步骤三:绘制直方图显示各数字出现频次
plt.figure(figsize=(10,6))
sns.histplot(df['number'], bins=range(1, 49+1), kde=True)
plt.title('Number Frequency Distribution')
plt.xlabel('Number')
plt.ylabel('Frequency')
plt.show()步骤四:计算平均值、中位数及标准差
mean_value = np.mean(df['number'])
median_value = np.median(df['number'])
std_deviation = np.std(df['number'])
print(f"Mean: {mean_value}, Median: {median_value}, Std Dev: {std_deviation}")通过以上几步简单的操作,我们就可以获得关于该段时间内六合彩号码分布的一些基本信息,这只是冰山一角,如果想要进一步挖掘更深层次的信息,还需要掌握更多高级的技术手段。
尽管利用统计学方法可以从一定程度上提高选号成功率,但值得注意的是,彩票本质上仍然是一种概率游戏,没有任何人能够保证百分之百中奖,在参与此类活动时务必保持理性态度,切勿盲目跟风投资,合理规划个人财务也是十分重要的一点,避免因过度沉迷而导致不必要的经济损失。
“二四六香港天天开彩大全”为我们提供了一个很好的学习平台,让我们有机会接触到真实世界中的大数据应用场景,希望通过今天的分享,能让更多感兴趣的朋友了解到数据分析的魅力所在,并在今后的生活中灵活运用相关知识解决问题。










 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号
还没有评论,来说两句吧...